Strings
Introdução
Representação de Caracteres:
Já vimos que computadores são excelentes para lidar com números. Na verdade, computadores são capazes de lidar apenas com números. Lembre-se que tudo em um computador é representado por meio de números em código binário.
Mas então como nós conseguimos trabalhar com letras e palavras?
No computador, os caracteres, i.e., letras, algarismos, sinais de pontuação, comandos de controle e vários outros símbolos, são armazenados por meio de um código numérico.
Cada símbolo recebe um código único. Por exemplo, em ANSI C, a letra ‘A’ maiúscula tem o código 65.
char c = 'A';
printf("%c = %d\n",c,c);
No terminal.
$ A = 65
Existem diversos padrões para definir tanto os códigos quanto a forma de armazenar caracteres. Ex.: EBCDIC, ASCII, ISSO-8859, UTF-8, UTF-16, etc.
Em ANSI C, usamos o padrão ASCII (American Standard Code for Information Interchange). Nesse formato, cada caractere ocupa 1 byte (8 bits) e existem 256 símbolos diferentes. Uma variável do tipo char guarda exatamente 1 caractere.
Tabela ASCII
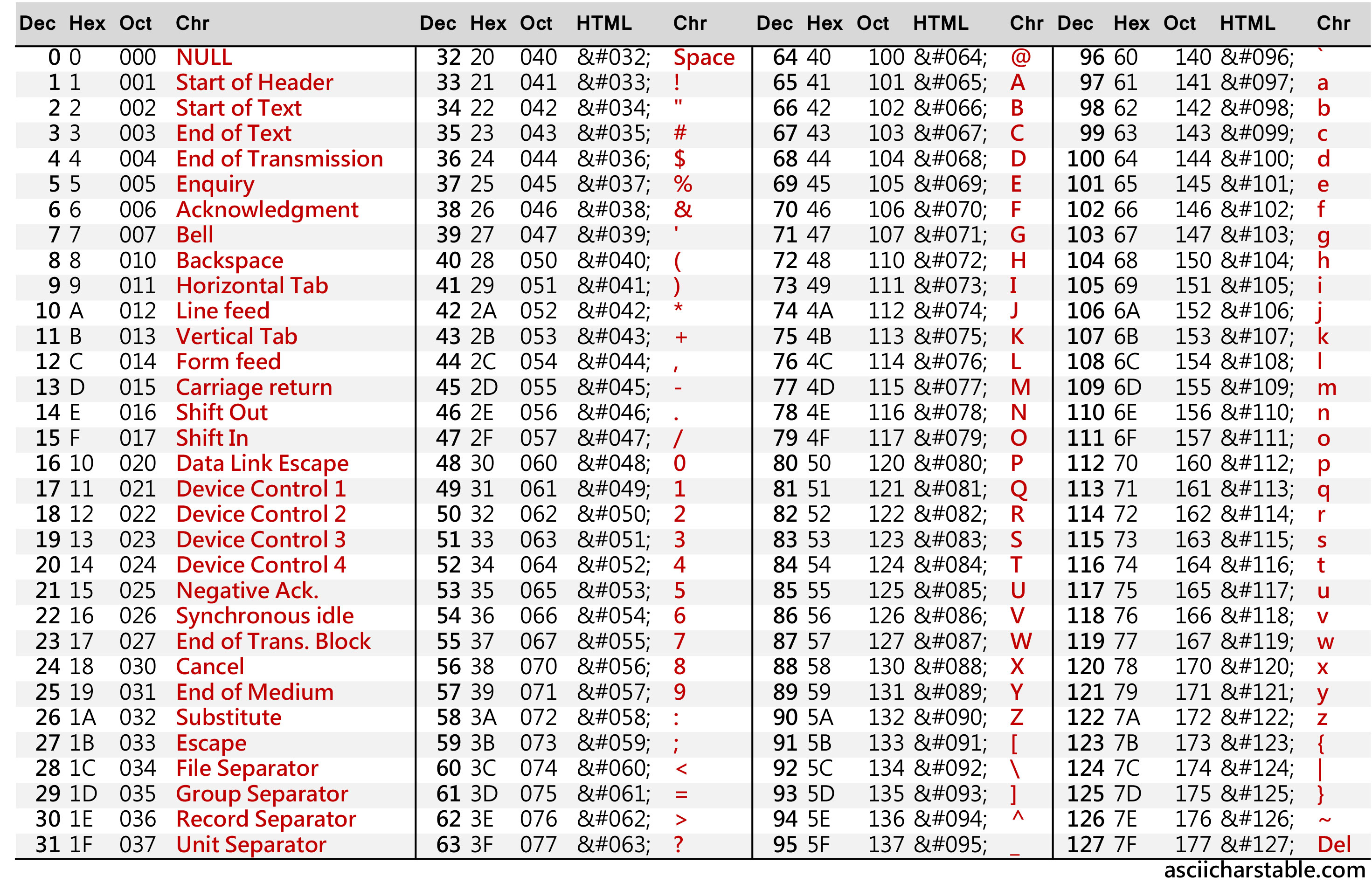
O comando $ man ascii no terminal mostra uma cópia da tabela ASCII acima
Strings
Sequência de Caracteres
Se um char guarda um caractere, então uma frase ou palavra nada mais é que uma sequência de chars, que também chamamos de string. Podemos usar um vetor para armazená-la.
char string[100]; // sequência de até 100 caracteres
Mas para manipular strings, o computador precisa saber onde a sequência termina. Como fazer isso?
Podemos guardar o tamanho da string, como fazemos com vetores em geral...
Ou podemos colocar uma marca no final da string, logo após o último caractere.
Essa última opção é mais interessante, pois evita que precisemos guardar o tamanho da string em uma variável separada ou passá-lo como um parâmetro extra de uma função.
A linguagem C trabalha com essa última abordagem.
Portanto, na nossa representação, uma string é um vetor de caracteres, e seu final será indicado por uma posição do vetor contendo o valor NULO. Em C, esse valor é indicado por '\0' (lê-se “barra zero”).
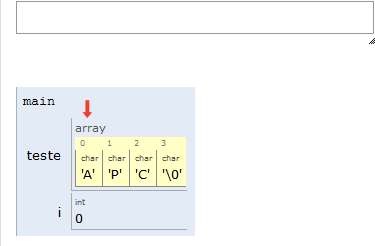
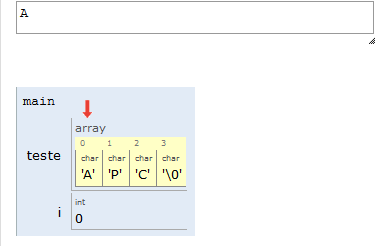
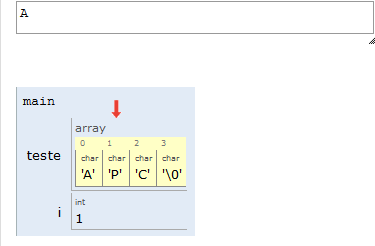
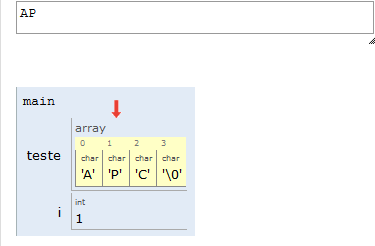
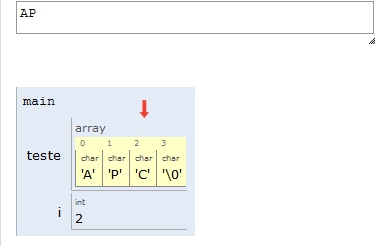
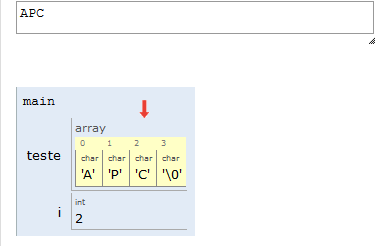
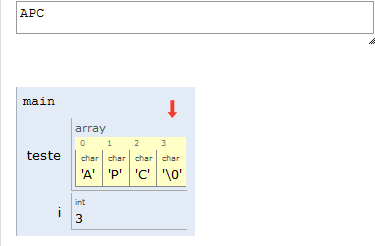
Por conta do '\0' no final das strings, lembre-se de sempre alocar um espaço a mais para suas strings.
Dado que as strings são vetores, podemos fazer uma série de operações sobre elas:
Encontrar o tamanho de uma string;
Concatenar duas ou mais strings;
Acessar um elemento (caractere) específico;
Extrair substrings;
Comparar duas strings segundo algum critério;
Ordenar os caracteres segundo algum critério;
Dentre outras.
Biblioteca <string.h>
Claramente podemos implementar nossas próprias funções para resolver os problemas destacados acima, como faremos nas aulas práticas, mas existe uma biblioteca que já trás muitas dessas funções prontas. É a biblioteca string.h. Vejamos alguns exemplos simples.
Lembre-se de incluir a bibliotaca de strings para poder usá-la no seu programa com #include <string.h>
- Verificar tamanho da string
// (precisa terminar em '\0') // ['U''m''a'' ''s''t''r''i''n''g'' ''q''u''a''l''q''u''e''r''\0'] char str[20] = "Uma string qualquer"; int size; size = strlen(str); // recebe 19 - Copiar uma string em outra
// (verifique que o espaço no destino é suficiente) char ink[15] = "Some text"; // ['S''o''m''e'' ''t''e''x''t''\0''\0''\0''\0''\0''\0'] char blank[15]; // ['\0''\0''\0''\0''\0''\0''\0''\0''\0''\0''\0''\0''\0''\0''\0'] strcpy(blank, ink); printf("Ink = %s\n", ink); printf("Blank = %s\n", ink); // Blank e Ink agora contém o mesmo texto // A saída no terminal ficaria // $Ink = Some text // $Blank = Some text // $ - Concatenar strings
// (verifique que o espaço no destino é suficiente) char hello[15] = "Hello "; // ['H''e''l''l''o'' ''\0''\0''\0''\0''\0''\0''\0''\0''\0'] char world[15] = "World!"; // ['W''o''r''l''d''!''\0''\0''\0''\0''\0''\0''\0''\0''\0'] strcat(hello, world); // adiciona World! ao final de Hello printf("%s\n", hello); // saida ficaria: // $Hello World! // $ - Ler string com espaço
// Declarando strings char name1[1000]; char name2[1000]; // Lê tudo do teclado até o enter (lê os espaços) scanf("%[^\n]s", name1); // Lê tudo até encontrar um espaço ou enter. scanf("%s", name2); // Imprime as palavras printf("Name 1 = %s\n", name1); printf("Name 2 = %s\n", name2);Ou seja, a diferença de um para o outro é que umscanf("%s", variable)lê todos os caracteres digitados enquanto não encontrou um enter ou um espaço, enquanto oscanf("%[^\n]s",variable)lê todos os carcteres digitados enquanto não encontrou somente um enter.Observação : Caso ao utilizar o
scanf("%s", variable)o usuário digitar mais de 1 palavra com espaço, da segunda palavra em diante não será salvo na variável e ficará no buffer do teclado, podendo usar outro scanf para ler o que ficou no buffer. - Para outros exemplos veja a documentação da biblioteca. Basta clicar na função de interesse.
Aplicações
Agora vamos explorar algumas aplicações em que empregamos strings.
DNA Complementar
Esta foi uma das questões da maratona de programação do IFB realizada em 12 de maio de 2018. Ela involve calcular a fita complementar de um DNA dado como string.
Explicação: Uma molécula de DNA é composta de duas fitas em forma de dupla-hélice contendo vários
pares de base nitrogenada. Os membros de um par de base nitrogenada estão um em cada
fita e cada base pode ser uma Adenina(A), Citosina(C), Guanina(G) ou Timina(T).
Os pares de base nitrogenada são ligados por pontes de hidrogênio, de modo que uma Adenina de uma Fita só pode se ligar a uma Timina de outra fita (A-T), já uma Guanina de uma fita só pode se ligar a uma Citosina de outra fita (C-G). Assim, a partir de uma fita é possível determinar exatamente quais as bases que estarão na fita complementar.
Em uma extremidade de uma fita de DNA, uma hidroxila do carbono-5 está livre enquanto na outra extremidade desta mesma fita, a hidroxila do carbono-3 é que estará livre. É neste sentido (5’3’), que o processo de replicação se inicia. Na fita complementar este sentido é invertido. Então temos uma situação assim:
Fita superior no sentido 5'3'-> 5’ ACTTAACTAACTG 3’
|||||||||||||
Fita inferiot no sentido 3'5'-> 3’ TGAATTGATTGAC 5’
Problema: Criar um programa que calcula a fita complementar, no sentido 5'3', de uma fita de DNA dada também no sentido 5'3'. A fita pode ter até 106 bases.
#include <stdio.h>
#include <string.h>
// Calcula o complementar do DNA no sentido correto para a saída
void comp(char* dna, int n, char* comp){
int i;
char ch;
// Percorrer fita original de trás para a frente. Escrever a nova de frente para trás.
for(i = 0; i < n; i++){
// A - T; C - G;
ch = dna[n-i-1]; // char original
if(ch == 'A'){
comp[i] = 'T';
}
else if(ch == 'T'){
comp[i] = 'A';
}
else if(ch == 'C'){
comp[i] = 'G';
}
else{
comp[i] = 'C';
}
}
comp[n] = '\0'; // fim da string
}
int main(){
// max de 106 bases
char dna[1000005];
char compl[1000005]; // string resposta
scanf("%s", dna); // nao precisa de & antes de string
int n = strlen(dna);
comp(dna, n, compl);
printf("%s\n", compl); // mostra resposta
}
Code Execution
Download Code
Pangrama
Explicação: Pangrama, ou pantograma, é uma frase em que são usadas todas as letras do alfabeto de determinada língua.
Problema: Dada uma frase, verificar se esta frase é ou não um pangrama. Um dos pangramas mais conhecidos é "The quick brown fox jumps over the lazy dog."
#include <stdio.h>
#include <string.h>
int ehMaiuscula(char ch){
// 'A' 'Z'
if((ch >= 65) && (ch <= 90))
return 1;
return 0;
}
int ehMinuscula(char ch){
// 'a' 'z'
if ((ch >= 97) && (ch <= 122))
return 1;
return 0;
}
// 1 = true; 0 = false
int ehPangrama(char* frase){
int alfabeto[26]; // alfabeto
memset(alfabeto, 0, sizeof(alfabeto)); // inicia tudo com 0 (false)
int l = strlen(frase), i;
// conta letras
for(i = 0; i < l; i++){
char ch = frase[i];
if(ehMaiuscula(ch)){
alfabeto[ch - 'A']++;
}
else if(ehMinuscula(ch)){
alfabeto[ch-'a']++;
}
// caracteres não alfabeticos nao acontece nada
}
for(i = 0; i < 26; i++){
if(alfabeto[i] == 0){
return 0; // false
}
}
return 1; // true
}
int main(){
char frase[1000000];
scanf("%s", frase);
int b = ehPangrama(frase);
if(b)
printf("A frase eh um pangrama\n");
else
printf("A frase NAO eh um pangrama\n");
}
Code Execution
Download Code
Exercícios Recomendados
Materiais Extras
Tabela ASCII
Tendo como base a tabela ASCII, é possível fazer diversas operações com string, tais como:
- Transformar um char com um dígito em número e vice e versa:
int char2int(char digito){ int num = digito - '0'; return num; } char int2char(int digito){ char num = digito + '0'; return num; }Usando este método, qualquer char com apenas 1 dígito pode ser transformado para int e vice versa, pois os chars '0','1',...,'9' estão em sequência na tabela, e o '0' possui o valor 48 na tabela ASCII, então qualquer número somado com 48 irá representar o seu valor em char. Por exemplo o número 4 somado com 48 é igual a 52, sendo o char '4' na tabela ASCII.
Já para transformar um char em um número basta subtrair a base, então o char '3', que possui o valor 51 na tabela ASCII, subtraido de 48 (caracter '0') é igual a 3, exatamente o dígito que queríamos. - Transformar letra minúscula para maiúscula e vice e versa:
char inverte(char letra){ if(letra >= 97 && letra <= 122) letra -= 32; else letra += 32; return letra; }Essa função funciona pois qualquer letra minúscula está no intervalo de 97 até 122 na tabela ASCII, e qualquer letra maiúscula está no intervalo de 65 até 90. Analizando a tabela, a distância de qualquer letra para sua respectiva maiúscula ou minúscula é de 32, por isso basta apenas somar 32 para que o 'C', 67 na tabela ASCII, vá para o número 99 que é o código do char 'c', e subtrair 32 para voltar.
Observação : Este método só funciona para números com apenas um dígito.
Byte addressing
Se escrever em um arquivo de texto a palavra "APC" e salvá-lo (exemplo: apc.txt), é possível gerar um arquivo em hexadecimal correspondente ao arquivo com o comando:
$ xxd apc.txt > apcEmBinario.txt
O arquivo apcEmBinario.txt será mais ou menos como esse.




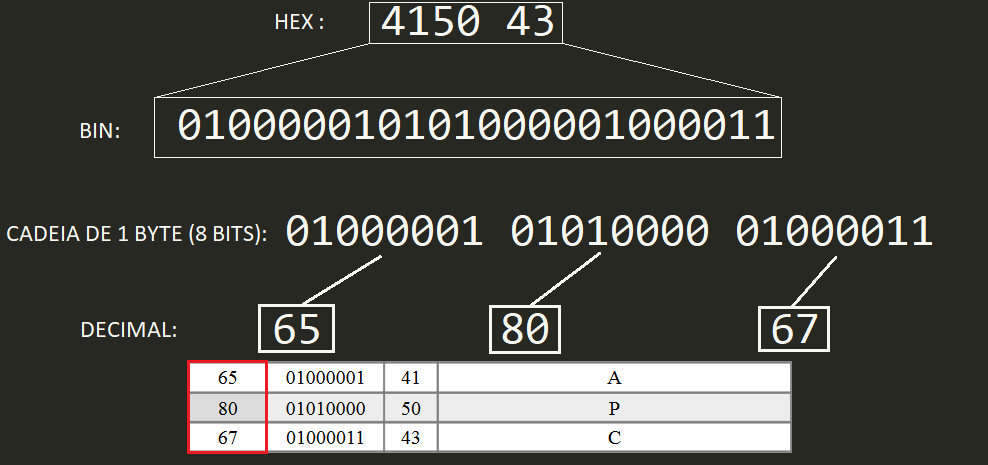
Isso acontece porque cada char ocupa exatamente 1 byte. Desta forma, a representação binária do arquivo (saída do comando xxd) traduz exatamente os códigos dos caracteres utilizados no texto. Lembre-se que cada dígito hexadecimal corresponde a 4 dígitos binários. Assim, 2 dígitos hex representam 8 bits, ou seja, 1 byte.